Ad
生成AI(人工知能)に「Let's think step by step(一歩一歩考えてみよう)」と指示すると、複雑な問題の正答率が上がる。この奇妙な発見を記した論文は世界の研究者を驚かせ、引用回数は4000回を超えた。執筆したのは、東京大学の小島武特任助教。文系のバックグラウンドを持ち、民間企業での勤務を経てAI研究の道に進んだ異色の研究者だ。
アカデミアにおけるAI研究の最前線に身を置く小島さんに、米国の巨大IT企業がAIの研究開発を席巻する今、どのようなテーマに日本の将来性や活路を見いだしているのか聞いた。
大規模言語モデル(LLM)に考えさせたら良い
―AI研究者としては非常に珍しい経歴です。この道に進んだ経緯を教えてください。
学部生時代に専攻した国際関係学はリベラルアーツ的な学問分野で、学際的な研究志向と英語力が身に付きました。民間企業でシステムエンジニア(SE)として働き、退職後に通った修士課程では、経済学の中でも計量計算学のモデルを使った実証分析を行ったのですが、理論から実証を行う点が後に進む理系分野と通ずるものがありました。
ちょうどその頃、米グーグルが教師なし学習で猫の概念を獲得するAIの構築に成功したというニュースを知り、「ディープラーニング(深層学習)がすごいらしい」との噂を耳にするようになります。国際関係学で得た英語力と経済学で学んだ統計的知識、そしてSEで身に着けたプログラミングスキルはAI研究とも相性が良かったので、思い切って博士課程からAI研究の道に足を踏み入れました。
当時は自然言語処理と画像認識が異なる専門分野として扱われ、どちらかに特化した研究室が多かったように思いますが、私が門を叩いた東京大学・松尾豊先生の研究室には、それらを同じものと捉えてつながりを見いだし、モダリティ(様式)の統合を試みる高い視座がありました。一つの研究室の中でさまざまな専門分野の研究者と交流しながら研究ができる点も合っていたように思います。
―「ステップバイステップ論文」も非常にユニークです。このフレーズはどのように考え出したのですか。
生成AIに数学の文章問題のような複雑な問題を解かせる方法を試行錯誤しているときに、偶然思いつきました。当時さまざまなやり方を試していたのですがインパクトのある成果が出ず、完全に行き詰まっていました。
そのとき、ふと「人間が考えたらダメかもしれない。生成AIのもととなる大規模言語モデル(LLM)が賢いのなら、LLM自身に考えさせたら良いのではないか」と思いました。同時に「Let's think step by step」というフレーズが降りてきたので、ダメ元で打ち込んでみたら「あれ、なんかうまくいった」といった具合でした。複雑な課題に対してその一文を入れただけで、LLMが自分で考えて見事に答えを出してくれました。本当に不思議でした。
内部挙動を解析し、効率化図る研究が盛んに
―特集ではAIの基本原理を考えた一人である甘利俊一さん(理化学研究所)にも取材をしています。生成AIの賢さに人間が追いつけていないと指摘していました。
私もそう思います。自分が貢献できるとすれば、実験的な解析によって理論を明らかにすることですね。
今、生成AIの内部挙動を解析する研究が盛り上がっています。例えば、メカニスティックインタープリタビリティー(機械論的解釈可能性)という分野では、ブラックボックス化されたモデルの内部をのぞき見るように調べています。この研究はAIの原理を解き明かす一つの方向性を示していて、とても重要だと思っています。今後もっと盛り上がるのではないでしょうか。私も力を入れて取り組んでいる研究の一つです。
―機械論的解釈可能性はどのような目的で盛んになっているのですか。
大きな理由は効率化ですね。AIの(挙動の)中身が明らかにならないと、上手く効率化を図れません。
AIの性能は計算に用いるLLMの規模に比例します。これを「スケール則」といい、基本的に生成AIを開発している企業はその法則に基づいてサーバーにたくさんの投資をし、どんどん学習させることでAIの性能を良くしています。ただ、スケール則には消費電力も含めてコストが非常にかかります。
右肩上がりに増えていくコストは、今後とても大きな課題になるでしょう。これからはより賢く、より効率の良いモデルに学習させる仕組みが必要です。もっと上手いやり方があるはずです。例えば人間の脳は、ほとんど電力を使わずに思考ができますから。
グーグル凌駕する機械学習モデルを
―今、小島さんはどのような研究に取り組んでいるのですか。
チームをいくつか作って、多方面に展開しています。一つはAIモデルの改善。先ほど話した効率化や軽量化のほかに、新しいモデルの開発がテーマです。現在の生成AIはディープラーニングの手法を用いていて、基軸になっているモデルは米グーグルが開発した「トランスフォーマー(Transformer)」です。2017年に発表され、すぐに世界を席巻しました。野心的な研究にはなりますが、トランスフォーマーを凌駕する次世代モデルを作れないかと取り組んでいます。
また、今のAI開発は、最初に事前学習で汎用的な能力を手に入れて、次の段階で医療や法律などに特化させています。これを「ドメイン特化」といい、人間が暗黙的に認識している法律や会社の規則などルール面をAIにも守らせるようにすることが大事なポイントです。では、どうやって守らせるか。そしてどうなると守れなくなるのか。その手法や、限界点を探る研究をしています。
そのほか、AIの安全性についての研究や、AIを自分の代理のように使うAIエージェントの研究もしています。私は性格的にさまざまな方面に興味を持ってしまうタイプなので、どうせだったらチームをたくさん作って一つでも多くやろうと思い、今は複数のテーマを同時並行で進めています。
―ほかにAI研究のトレンドとして見据えているものはありますか。
AIの「身体性」が今後のトレンドになると見ています。現状、AIは知能だけの存在で身体を有していません。そこでインターフェースとしてロボットを組み合わせる研究に注目が集まっているのです。実際、イーロン・マスク氏率いる米テスラが、機能はまだまだ限られているもののAIロボットの発売を2026年に予定しています。
ただ、これらが人間に置き換わる存在になるとは思っていません。人間の心理は、人間にしか分かりませんから。私個人としては、少子化が進む中で人間の暮らしや産業を補う存在になってくれればと期待をしています。
グレーゾーンなくし、優れた人材集まるいい流れを
―中国のディープシーク社が話題をさらっていますが、どのように捉えていますか。
米国以外の組織が世界的に最先端のLLMを、しかも低コストで開発・公開したことに衝撃を受けています。彼らのモデル学習で使われている技術(ルールベースの報酬による強化学習)が性能の飛躍的改善に有効であるかもしれないことは、研究としても非常に興味深い。オープンAIのデータを使ったのではないかというニュースも流れており、真偽が気になるところで注目しています。また今後、日本からもこのような世界的に最先端のモデルが開発されることを期待したいですね。
―では、日本の現状をどのように見ていますか。
AIに限った話ではありませんが、ここ数十年、日本がプラットフォーマー(基盤提供事業者)になれていない事実は重い鉛となっている気がします。かつてはVHSなどの世界基準を次々に生み出せていたことを考えると、この状況を何とかしたい思いはありますね。その点AIはちゃぶ台返しの連続です。次の局面でチャンスが訪れるかもしれません。
―AI研究において日本の強みとなる部分はどんなところにあるとお考えですか。
日本はAIに対して規制がそれほど厳しくありません。それで今、優れた人材や組織が日本に集まり始めています。例えば、米マイクロソフトはAIの研究拠点を東京に新設しました。良い流れができつつあると思います。AIの研究は、結局はソフトの研究です。優れた人材が集まって、研究や開発がやりやすい環境も整えば、新しいものが生まれやすくなります。
ただ、ルール面ではグレーゾーンが残っているので、今後そこがどうなっていくのかが気になります。主には著作権やライセンス、個人情報の問題などですね。このあたりは諸外国からの致命的な遅れにつながりかねません。
特に、個人情報の扱いについてはグレーゾーンがかなりあるようです。ここを法的にきちんとしないと、開発のスピードが落ちる可能性があります。他国はリスクを承知でグレーゾーンを踏みにいく例も見られますが、日本にはなじまない考え方なので、早急にグレーゾーンをなくす取り組みを進めたほうが良いと思います。
AI研究者は常にフレッシュでいるべき
―AIの研究や開発におけるアカデミアの役割は何だと思われますか。
生成AIは、開発自体が研究そのものになる側面があります。規模を大きくすることで新たなタスクができるようになったり、ベンチマーク(基準)が非常に上がったりするので、それだけで研究として成り立ちます。
でも、それは既存の技術を伸ばす「開発」であって、「研究」とは少し違うと私は思っています。研究は、何もない状態から新しいものを生み出すこと。つまり、開発が1を1万とか100万に引き上げる営みだとすれば、0から1を生み出すところにアカデミアの役割があるのではないか、その本質的な役割は今も昔も変わらないと思います。
―日本で0から1を作るAI研究を実現するために必要なことは何でしょう。
研究者個人の志としては、敏感であること、保守的にならないこと、常にフレッシュでいることが大事だと思います。移り変わりの早い分野ですので。そしてAI研究を日本全体で盛り上げるには、やはり人材と資金が肝になるでしょう。それを支えるエコシステムが、各地にたくさん作られていくことに期待したいです。



 「ステップバイステップ論文(正式タイトル『Large Language Models are Zero-Shot Reasoners』)」生みの親である小島武さん
「ステップバイステップ論文(正式タイトル『Large Language Models are Zero-Shot Reasoners』)」生みの親である小島武さん GPT-3が誤答した問い(左)に「Let's think step by step」を追加したところ(右)正しい回答を導き出すことができた(小島さん提供)
GPT-3が誤答した問い(左)に「Let's think step by step」を追加したところ(右)正しい回答を導き出すことができた(小島さん提供)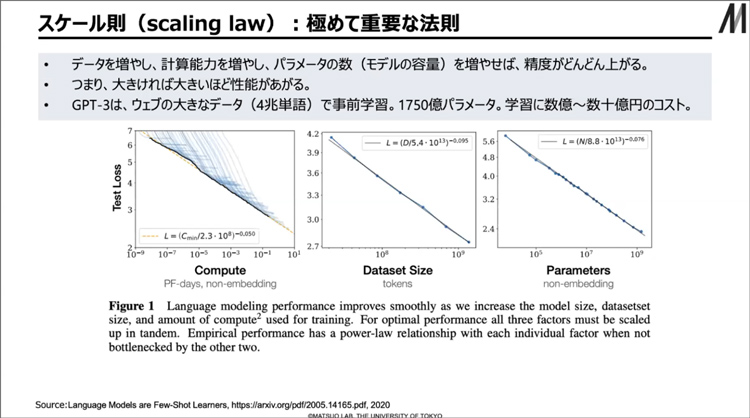 AIの性能がLLMの規模に比例することを示したスケール則。コストが大きな課題になっている(東京大学松尾・岩澤研究室提供)
AIの性能がLLMの規模に比例することを示したスケール則。コストが大きな課題になっている(東京大学松尾・岩澤研究室提供)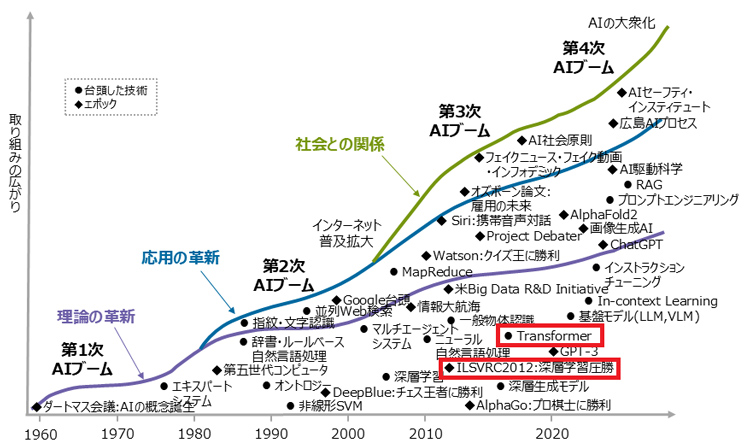 ディープラーニングは画像認識大会「ILSVRC2012」で優勝したトロント大学の「AlexNet(アレックスネット)」の精度の高さによって注目が高まった。2017年登場のトランスフォーマーは長く主軸モデルとして君臨している(JST研究開発戦略センター作成の図を一部改変)
ディープラーニングは画像認識大会「ILSVRC2012」で優勝したトロント大学の「AlexNet(アレックスネット)」の精度の高さによって注目が高まった。2017年登場のトランスフォーマーは長く主軸モデルとして君臨している(JST研究開発戦略センター作成の図を一部改変) 理化学研究所の研究チームは、ヒューマノイドロボット「まほろ」とAIを組み合わせ細胞の自律培養を実現している(JST撮影)
理化学研究所の研究チームは、ヒューマノイドロボット「まほろ」とAIを組み合わせ細胞の自律培養を実現している(JST撮影) 小島武さん
小島武さん




